
2020년 10월 15일 Google 검색의 최신 정보, 향후 방향성에 대한 이벤트가 온라인 상에서 진행되었다. 아래 링크는 해당 유튜브 영상이다. 관심 있으신 분들은 보시면 좋을 것 같다. 길이는 약 36분.
Search On 라이브스트림에서 소개된 향후 구글검색의 업데이트 개선점은 7가지로 요약할 수 있다. 1) 일부 적용되고 있었던 BERT가 이제 모든 언어로 확대된다는 소식, 2) 문맥 이해도가 높아진다는 점, 3) 검색결과(SERP)에 서브 토픽들이 포함된다는 것, 4) 비디오 검색 시 비디오 내 키프레임이 출력된다는 점, 5) 데이터커먼 프로젝트를 활용한 통계 결과, 6) AR과 렌즈의 검색활용, 마지막으로 7) 흥얼거림 검색 등이다.
검색결과에 BERT 확대 적용
BERT는 Bidirectional 모델로 양방향 컨텍스트를 참조하는 구조를 갖는다. 따라서 필연적으로 구문이해에 높은 강점을 갖는다. 지금까지 불용어로 무시(?) 당해왔던 for, into 같은 단어들이 BERT로 인해 이제부터는 매우 중요해진다.
예를 들어, ‘서울에서 부산까지’라는 쿼리에 대해서 지금까지는 ‘서울’, ‘부산’이라는 키워드를 중심으로 검색결과를 출력했다면 이제부터는 ~에서를 정확히 이해한 후 검색결과를 출력할 수 있게 된다는 의미다.
BERT 알고리즘의 실제 예시들은 본 컬럼에서 다룬 적이 있다. Google(구글 검색)의 BERT 알고리즘 업데이트가 가지는 의미
구문 이해
구글 검색엔진에서 구문이해는 사실 오래 전부터 주요 과제였다. 이를 검색엔진의 ‘포괄적 문맥이해’라는 개념으로 볼 수 있는데, 인접한 문맥을 쌍으로 이해하고 (예를 들면, “read book Shakespeare Romeo and Juliet” 이라는 쿼리가 있을 때, “book”의 인접 용어 “read”와 쌍으로 인지-‘책을 읽는다’라고 이해할 수 있다.
이 때 만약 read 대신 play라는 단어가 들어와도 문맥이해는 동일하다. 대신 어순 등이 뒤바뀌게 될 경우, 이 문맥은 달라진다), 그에 맞는 검색결과를 출력하는 노력은 계속되어 왔다.
그런데 지금까지는 인접한 문맥(비교적 가까운 거리)을 파악하는 수준에 그쳤다면 BERT를 통해 문장 전체의 이해가 가능해지게 된다. 구문이해가 정밀하게 되면 될수록, 자연어 검색의 향상으로 이어질 수 있다. 아직까지 음성검색은 만족스럽지 못할 때가 많지만, 앞으로는 꽤 만족스러운 검색결과를 기대해 볼 수 있지 않을까?
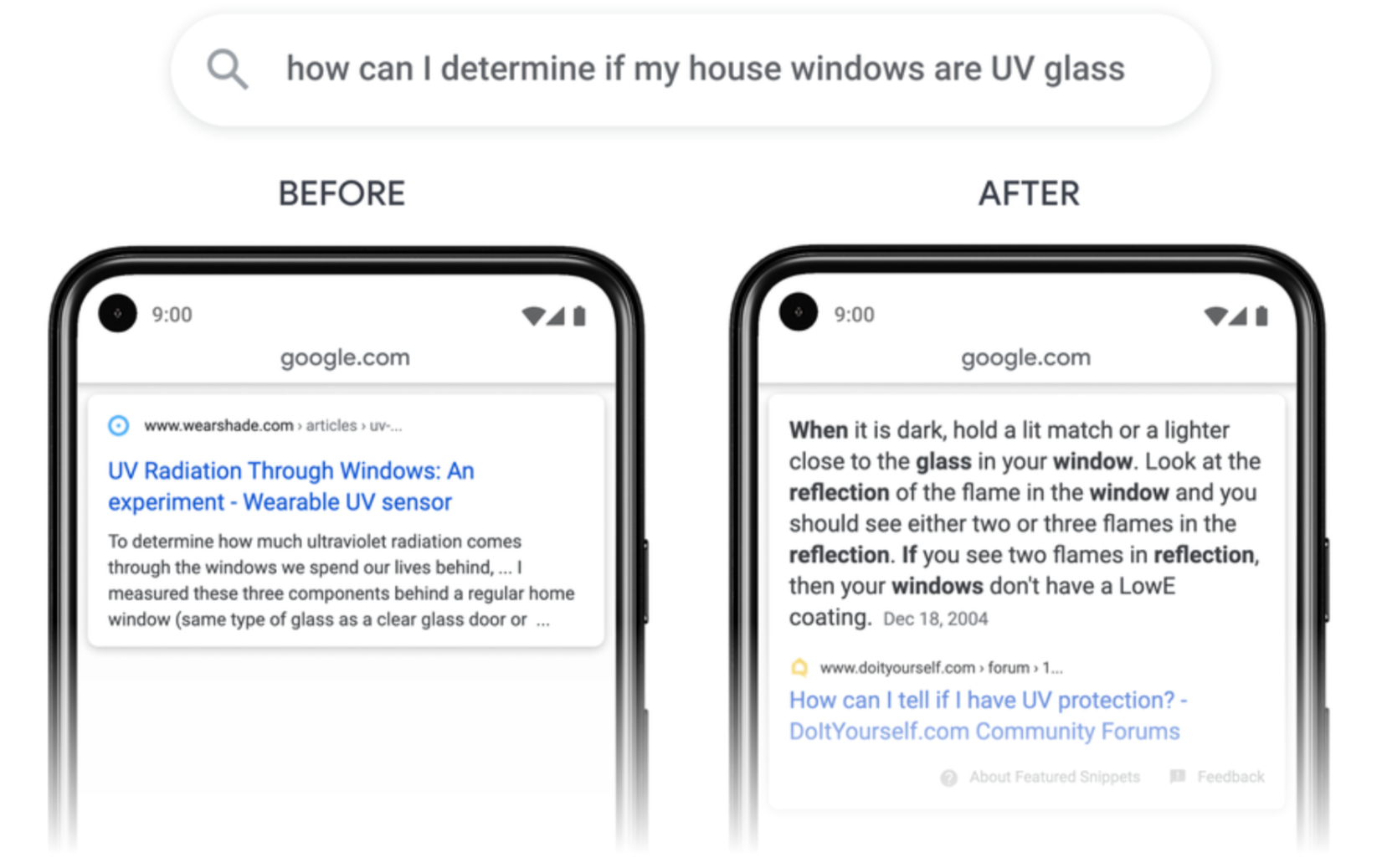
서브 토픽
필자가 구글검색을 설명할 때 자주 드는 예시는 ‘구글=도서관 사서’라는 개념이다. 거대한 도서관이 있고, 어떤 정보를 찾고자 하는 사람이 도서관의 사서에게 정보를 찾아달라고 요청하는 이미지를 떠올려 보자.
만약 당신이 어떤 정보를 이 도서관 사서에게 요청한다고 가정할 때, 당신의 요청이 구체적일수록 도서관 사서의 일 또한 쉬울 것이다. 예를 들어, ‘주식회사 어센트’ 관련 정보를 찾는다라고 한다면, 도서관 사서는 그 정보(어센트 홈페이지)를 바로 찾아줄 것이다.
그런데 만약 당신이 ‘일본’에 대한 정보를 찾는다고 한다면, 사서는 어떤 정보를 제시해 주어야 할까? 이것을 브로드 키워드의 문제라고도 하는데, ‘일본’과 같은 브로드한 주제를 찾을 경우 도서관 사서가 내놓는 가장 현명한 답은 일본 관련된 서브 주제들을 대부분 담고 있는 결과(구글에서 일본을 검색해 보면, 위키피디어가 출력된다)를 제시할 수 밖에 없다. 그렇기 때문에 검색, SEO, 그리고 컨텐츠 마케팅에 있어서 토픽은 여전히 중요한 테마다.
이번 발표 내용을 살펴보면 ‘일본’ 같은 브로드 키워드 뿐만 아니라, 비교적 작은주제인 ‘가정용 운동기구’ 같은 쿼리에 대해 ‘예산’, ‘장비’, ‘작은 공간’ 같은 하위주제들을 검색결과에 출력해 준다고 한다. 이 부분은 SEO에 있어서 많은 고민을 던져줄 것으로 예상된다.

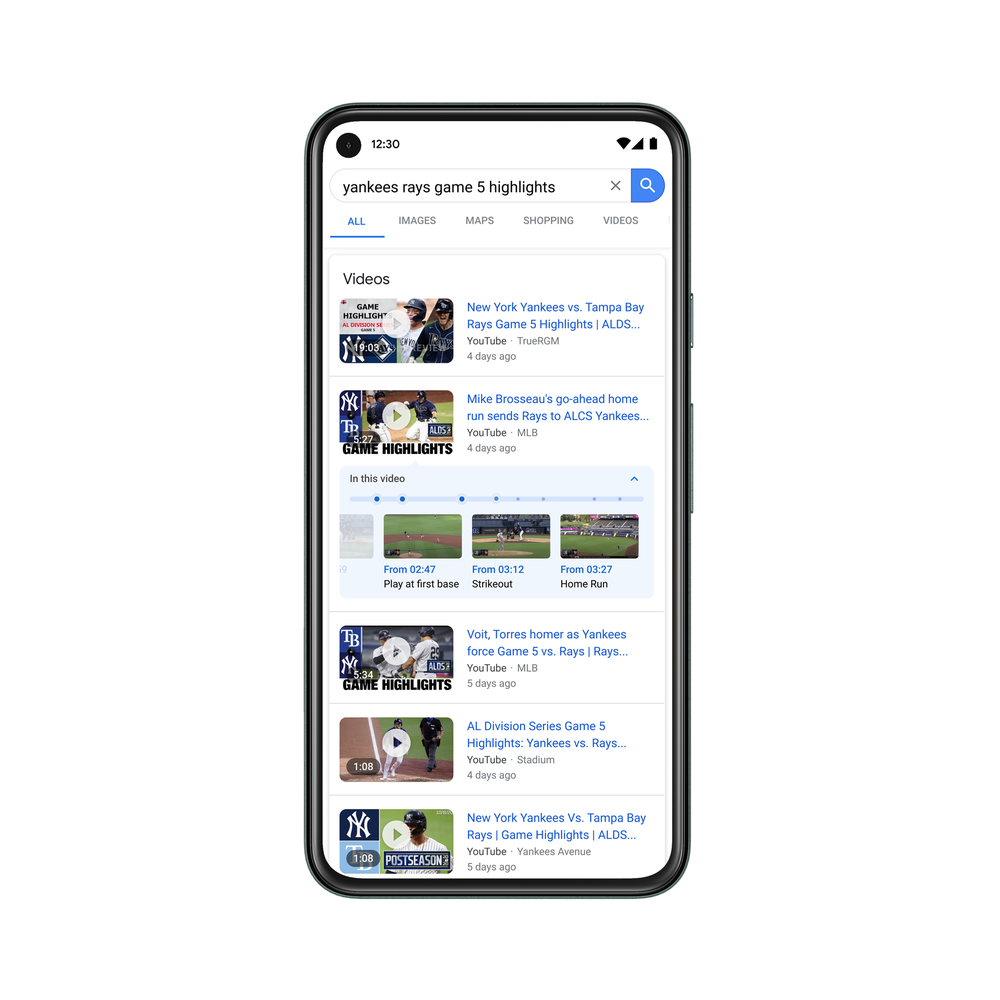
검색결과에 비디오 키 프레임 출력
비디오 검색(유튜브 검색)은 날이 갈수록 높아지고 있다. 어떤 정보에 따르면 유튜브 검색량은 구글의 1/5 수준까지 높아졌다고 한다.
언젠가 한번 소개하고 싶은 주제이기도 한 ‘유튜브 검색 알고리즘’이지만, 사실 유튜브 검색 알고리즘 (정확히는 추천을 포함하는 [유튜브 랭크 알고리즘])은 구글 검색 알고리즘에 비해 많이 빈약한 새내기다.
그 첫번째 이유는 구글이 학습할 정보가 웹페이지보다 훨씬 부족하기 때문이다. 그래서 유튜브 랭크 알고리즘은 Co-Visit 같은 사용자 패턴 관련 인풋이 더 많이 사용된다. 그렇기 때문에, 유튜브에 접속하면, 특정 주제들로 치우쳐 있는 동영상들을 많이 보게 되는 것이다.
구글의 동영상 키프레임 이해는 CNN 등의 딥러닝 기술로 인해 예상되는 행보이긴 하지만 그 결과는 유튜브 검색결과에 많은 영향을 줄 것으로 예측된다. 썸네일과 자극적인 타이틀로 많은 조회수를 확보해 온 꼼수가 더 이상은 통하지 않을 것이다.
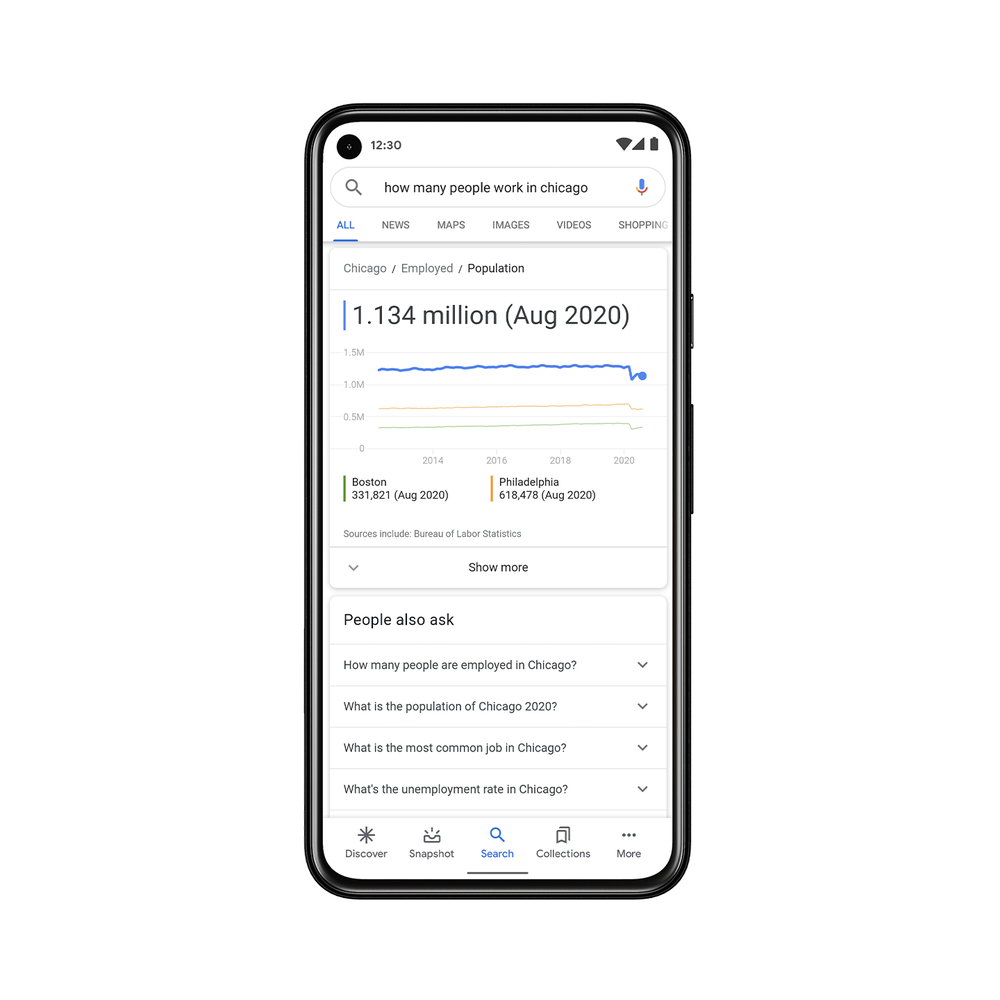
검색결과에 더 많은 통계자료
통계 데이터의 개방형 지식 데이터베이스 프로젝트인 Data Commons의 많은 정보들이 검색결과에 바로 반영될 예정이다. ‘시카고에서 일하는 사람 수’ 같은 쿼리에 대해 위 데이터 커먼즈의 통계데이터가 SERP에 바로 표시되어 마치 오늘의 날씨를 검색하는 것처럼 데이터 찾기는 더 빨라질 것이다.
렌즈와 VR을 통한 이미지와 3D 검색
렌즈 기능은, 우리가 익히 알고 있는 빅스비 비전과 같은 기능으로 크게 흥미롭진 않다. 또 이미지 검색 또한 핀터레스트가 이미 하고 있어서 그다지 새롭다는 느낌은 받을 수 없다.
검색결과가 AR로 출력되는 부분은 어떤 형태로든 AR로 제작된 (Volvo 및 Porsche와 같은 브랜드와 협력 중이라 함) 컨텐츠가 있어야 하기 때문에 초기에는 상위 브랜드들 중심으로 될 것 같지만, 이것이 보편화 된다면 ‘구글 지도’가 그랬던 것처럼 임팩트가 있을 것으로 기대된다.
흥얼거림 검색
흥얼거림을 통해서 음악을 검색하는 기능으로 상세 내용은 아래 참조페이지를 보길 권한다.
이상으로 간략하게 10월 15일에 있었던 Search On 라이브스트림을 소개해 보았다. 필자는 개인적으로 2021년 상반기 정도에는 구글 검색이 네이버 검색을 쉐어에서 넘어설 것으로 본다.
이제 한국의 마케팅 전문가들도 지금보다 좀 더 구글검색-구글광고에 민감해질 시간이 되지 않았나 생각해본다.